The Context Gap: Why Enterprise AI Projects Stall Between Proof-of-Concept and Production
24.04.2026What teams don’t know they need until it’s too late
We’ve spent the last few years helping enterprises build AI systems that actually work in production. Not just in notebooks, not just in demos, but in the messy reality of regulated industries, fragmented data estates, and teams that need to trust what AI tells them before they act on it.
The pattern we see over and over is simple: the model isn’t the problem. The context is.
The 80% Problem Nobody Talks About Honestly
Everyone quotes the stat. Most enterprise AI projects never make it to production. But having sat across the table from data teams at asset managers, insurers, retailers and logistics companies, we’d put it differently: most AI projects work. They just don’t work at scale.
A model that classifies claims accurately in a test environment fails in production because nobody mapped which upstream system owns the data it depends on, or what happens when that system’s schema changes on a Tuesday afternoon. A RAG pipeline returns confident answers, but the documents it retrieves are already outdated, and there is no lineage to catch the drift. A recommendation engine performs well until a compliance officer asks, “Where did this output come from, and who approved the data it was trained on?”
These are not edge cases. This is what normal looks like when AI meets the enterprise.
Most AI failures are not model failures. They are context failures.
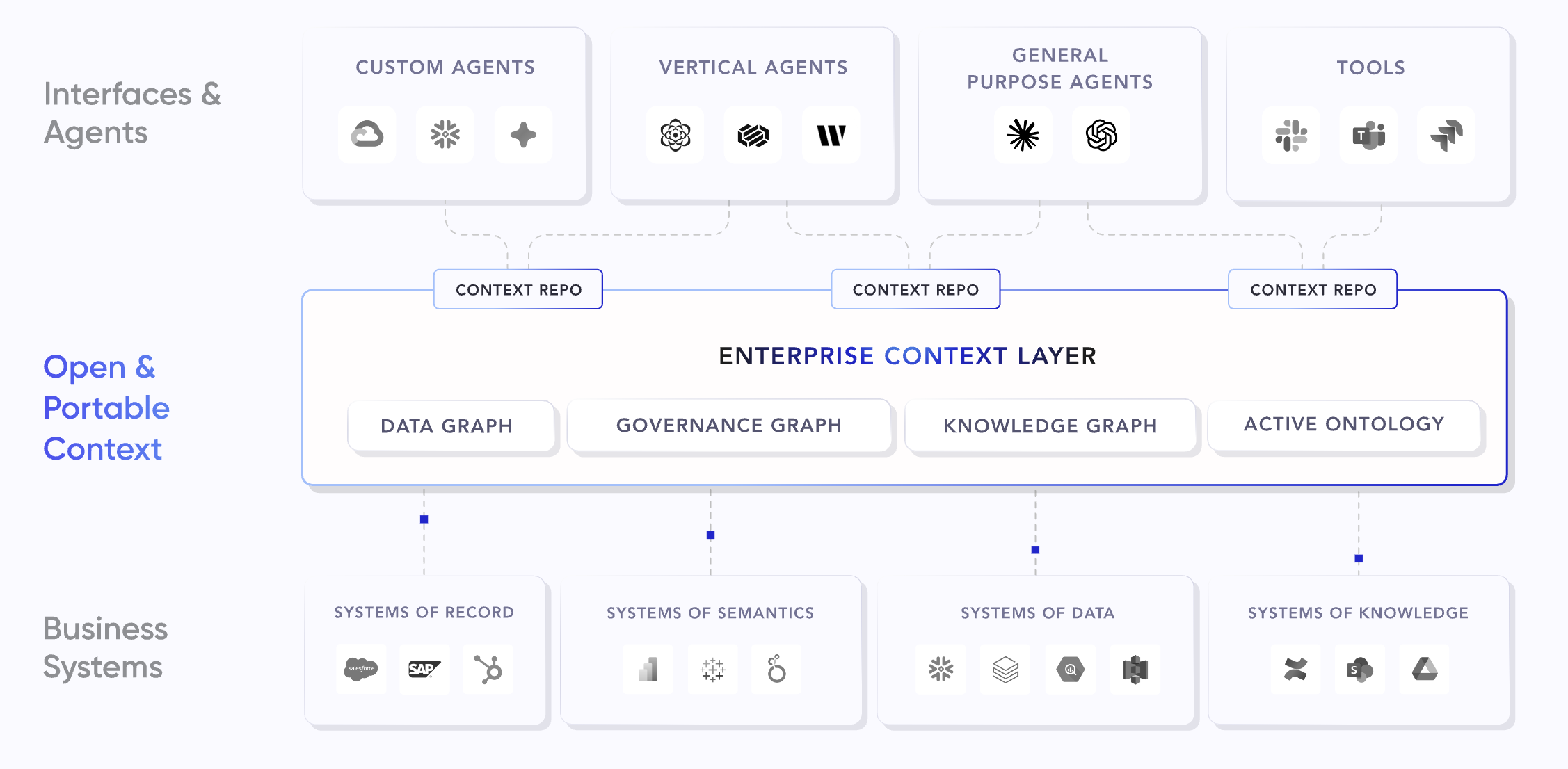
Context Is Not a Feature, It’s a Layer
When we say “context,” we don’t mean giving a model more tokens or stuffing a prompt with metadata. We mean the structure that tells you. In practice, it breaks down into five areas AI systems consistently lack: what the data is and where it came from; what it means in business terms; how it connects to other assets, decisions, and domain knowledge; what rules and policies govern its use; and who is accessing it and why..
This is not new. Most organisations already have parts of it in data catalogs, governance tools, and metadata systems. The problem is that those parts live in separate systems, maintained by separate teams, and are never compiled into something an AI system can use when it needs to act. In other words, context is rarely used when it matters.
It sits between the data infrastructure and the AI applications teams want to ship. Without it, AI systems are effectively flying blind. They might produce the right answer, but you cannot explain it or rely on it consistently.
What is changing is not what context is, but how it is used. Instead of being looked up by humans, it needs to be delivered to AI systems at the moment they make decisions. That is what we are now calling a context layer.
Context is not static. It changes as teams evolve, pipelines are refactored, and business rules shift. The organisations that succeed are not the ones with the best models, but the ones that keep this layer alive and usable.
What We See in the Field
At In516ht, we work across the full stack, from data platform architecture to AI application delivery. Across organisations that struggle to get AI into production, the pattern is consistent:
Data teams and AI teams operate in silos. The people who understand the data are not the ones building the models. Context should bridge that gap, but only if it is accessible, not locked in someone’s head or a stale Confluence page.
Trust is the real bottleneck. We have seen technically sound AI solutions shelved because the business could not verify where the data came from or explain outputs to regulators. Trust is not built by better models, but by traceability and transparency.
Governance gets bolted on too late. It is treated as a checkpoint instead of part of the system. By the time compliance gets involved, it is either too expensive to fix or already creating risk in production.
The Case for an Enterprise Context Layer
This is why the idea of an enterprise context layer resonates with what we see on the ground. It is not about adding another tool to the stack. It is about finally using what most organisations already have by making metadata, lineage, ownership, and governance usable.
When this context is active and connected, not just documented, the path from POC to production shortens. AI systems can retrieve not just data, but the meaning and constraints around it. Teams move faster because they are not rebuilding trust every time they deploy something new.
We have seen this with clients who invested in this layer early. Their AI projects do not just ship faster. They stay in production longer, scale more predictably, and pass compliance reviews without the usual last minute scramble.
Looking Ahead
AI is becoming a real part of enterprise operations. Systems are starting to take actions, orchestrate workflows, and make decisions. That raises the stakes around context.
An AI system without context is a liability. With clear ownership, governance, and lineage, it becomes something the business can actually trust and use.
The organisations that will lead in the next phase of AI adoption will not be the ones with the most advanced models. They will be the ones that understood early that context is a dependency, not an afterthought.That is the pattern we see. That is the gap we help close. And that is why we are working closely with Atlan, the Enterprise Context Layer for AI that makes metadata, lineage, ownership, governance, and business meaning accessible to agents the moment they need it. Not because the approach is new, but because Atlan is the first platform built to deliver it in a way that AI systems can rely on. And as a Context Layer Partner, In516ht is working alongside customers to make context accessible to every tool you run, at enterprise scale.
Business Development
